
إطار عمل NVIDIA NeMo

تحديد
- اسم المنتج:إطار عمل NVIDIA NeMo
- المنصات المتأثرة: ويندوز، لينكس، ماك أو إس
- الإصدارات المتأثرة: جميع الإصدارات قبل 24
- ثغرة أمنية: سي في إي-2025-23360
- درجة الأساس لتقييم المخاطر: 7.1 (CVSS الإصدار 3.1)
تعليمات استخدام المنتج
تثبيت تحديث الأمان:
لحماية نظامك، اتبع الخطوات التالية:
- قم بتنزيل الإصدار الأحدث من صفحة إصدارات NeMo-Framework-Launcher على GitHub.
- انتقل إلى أمان منتج NVIDIA للحصول على مزيد من المعلومات.
تفاصيل تحديث الأمان:
يعالج تحديث الأمان ثغرة أمنية في إطار عمل NVIDIA NeMo والتي قد تؤدي إلى تنفيذ التعليمات البرمجية وسرقة البياناتampإرينغ.
تحديث النظام:
إذا كنت تستخدم إصدار فرع سابق، فمن المستحسن الترقية إلى أحدث إصدار فرعي لمعالجة مشكلة الأمان.
زيادةview
NVIDIA NeMo Framework هو إطار عمل توليدي للذكاء الاصطناعي قابل للتطوير ومبني على السحابة ومُصمم للباحثين والمطورين الذين يعملون على نماذج لغوية كبيرة، متعدد الوسائط، و الذكاء الاصطناعي للكلام (على سبيل المثال التعرف التلقائي على الكلام و تحويل النص إلى كلام). إنه يتيح للمستخدمين إنشاء نماذج الذكاء الاصطناعي التوليدية الجديدة وتخصيصها ونشرها بكفاءة من خلال الاستفادة من الكود الحالي ونقاط تفتيش النموذج المدربة مسبقًا.
تعليمات الإعداد: تثبيت إطار عمل NeMo
يوفر إطار عمل NeMo دعمًا شاملاً لتطوير نماذج اللغات الكبيرة (LLMs) والنماذج متعددة الوسائط (MMs). كما يوفر مرونة الاستخدام محليًا، أو في مركز بيانات، أو مع مزود الخدمة السحابية المفضل لديك. كما يدعم التنفيذ في بيئات SLURM أو Kubernetes.

معالجة البيانات
نيمو أمين المتحف [1] هي مكتبة بايثون تتضمن مجموعة من الوحدات لاستخراج البيانات وتوليد البيانات الاصطناعية. تتميز هذه الوحدات بقابليتها للتطوير ومُحسّنة لوحدات معالجة الرسومات، مما يجعلها مثالية لمعالجة بيانات اللغة الطبيعية لتدريب أو تحسين أنظمة إدارة التعلم (LLMs). مع NeMo Curator، يمكنك استخراج نصوص عالية الجودة بكفاءة من بيانات خام واسعة النطاق. web مصادر البيانات.
التدريب والتخصيص
يوفر إطار عمل NeMo أدوات للتدريب والتخصيص الفعال ماجستير في القانون ونماذج متعددة الوسائط. يتضمن تكوينات افتراضية لإعداد مجموعة الحوسبة، وتنزيل البيانات، ومعلمات النموذج الفائقة، والتي يمكن تعديلها للتدريب على مجموعات بيانات ونماذج جديدة. بالإضافة إلى التدريب المسبق، يدعم NeMo تقنيات الضبط الدقيق المُشرف (SFT) والضبط الدقيق الفعال للمعلمات (PEFT) مثل LoRA وPtuning وغيرها.
هناك خياران متاحان لبدء التدريب في NeMo - باستخدام واجهة API الخاصة بـ NeMo 2.0 أو باستخدام NeMo Run.
- مع NeMo Run (موصى به): يوفر NeMo Run واجهة لتبسيط تكوين التجارب وتنفيذها وإدارتها عبر بيئات حوسبة متنوعة. يشمل ذلك تشغيل المهام على محطة العمل محليًا أو على مجموعات كبيرة - سواءً باستخدام SLURM أو Kubernetes في بيئة سحابية.
- التدريب المسبق والبدء السريع في PEFT مع NeMo Run
- استخدام واجهة برمجة التطبيقات NeMo 2.0: تعمل هذه الطريقة بشكل جيد مع إعدادات بسيطة تتضمن نماذج صغيرة، أو إذا كنت مهتمًا بكتابة مُحمّل بيانات مُخصص، أو حلقات تدريب، أو طبقات نموذج مُتغيرة. فهي تمنحك مرونة وتحكمًا أكبر في التكوينات، وتُسهّل توسيع التكوينات وتخصيصها برمجيًا.
-
تراالبدء السريع باستخدام واجهة برمجة التطبيقات NeMo 2.0
-
الانتقال من NeMo 1.0 إلى واجهة برمجة التطبيقات NeMo 2.0
-
تنسيق
- محاذاة نيمو [1] مجموعة أدوات قابلة للتطوير لمواءمة النماذج بكفاءة. تدعم هذه المجموعة أحدث خوارزميات مواءمة النماذج، مثل SteerLM وDPO والتعلم المعزز من التغذية الراجعة البشرية (RLHF)، وغيرها الكثير. تُمكّن هذه الخوارزميات المستخدمين من مواءمة نماذج اللغة لتكون أكثر أمانًا وفعاليةً وفائدةً.
- جميع نقاط تفتيش NeMo-Aligner متوافقة مع نظام NeMo البيئي، مما يسمح بمزيد من التخصيص ونشر الاستدلال.
سير العمل خطوة بخطوة لجميع المراحل الثلاث لـ RLHF على نموذج GPT-2B صغير:
- تدريب SFT
- تدريب نموذج المكافأة
- تدريب PPO
بالإضافة إلى ذلك، فإننا نظهر الدعم لمختلف طرق المحاذاة الجديدة الأخرى:
- مسؤول حماية البيانات: خوارزمية محاذاة خفيفة الوزن مقارنة بـ RLHF مع دالة خسارة أبسط.
- اللعب الذاتي الضبط الدقيق (SPIN)
- توجيه LM: تقنية تعتمد على SFT المشروطة، مع مخرجات قابلة للتوجيه.
راجع الوثائق للحصول على مزيد من المعلومات: توثيق المحاذاة
نماذج متعددة الوسائط
- يوفر إطار عمل NeMo برنامجًا محسنًا لتدريب ونشر نماذج متعددة الوسائط الحديثة عبر عدة فئات: نماذج اللغة متعددة الوسائط، وأساسيات اللغة البصرية، ونماذج تحويل النص إلى صورة، وما بعد ذلك من جيل ثنائي الأبعاد باستخدام حقول الإشعاع العصبي (NeRF).
- تم تصميم كل فئة لتلبية احتياجات محددة والتطورات في هذا المجال، والاستفادة من النماذج المتطورة للتعامل مع مجموعة واسعة من أنواع البيانات، بما في ذلك النصوص والصور والنماذج ثلاثية الأبعاد.
ملحوظة
نقوم بنقل دعم نماذج الوسائط المتعددة من NeMo 1.0 إلى NeMo 2.0. إذا كنت ترغب في استكشاف هذا المجال في هذه الأثناء، يُرجى مراجعة وثائق إصدار NeMo 24.07 (السابق).
النشر والاستدلال
يوفر إطار عمل NeMo مسارات مختلفة لاستنتاج LLM، بما يتناسب مع سيناريوهات النشر المختلفة واحتياجات الأداء.
النشر باستخدام NVIDIA NIM
- يتكامل إطار عمل NeMo بسلاسة مع أدوات نشر النماذج على مستوى المؤسسة من خلال NVIDIA NIM. يعمل هذا التكامل بتقنية NVIDIA TensorRT-LLM، مما يضمن استدلالًا مُحسَّنًا وقابلًا للتطوير.
- لمزيد من المعلومات حول NIM، قم بزيارة موقع NVIDIA webموقع.
النشر باستخدام TensorRT-LLM أو vLLM
- يوفر إطار عمل NeMo نصوصًا وواجهات برمجة تطبيقات لتصدير النماذج إلى مكتبتين محسّنتين للاستدلال، TensorRT-LLM وvLLM، ونشر النموذج المُصدَّر باستخدام NVIDIA Triton Inference Server.
- في السيناريوهات التي تتطلب أداءً مُحسَّنًا، يمكن لنماذج NeMo الاستفادة من TensorRT-LLM، وهي مكتبة متخصصة لتسريع وتحسين استدلال LLM على وحدات معالجة الرسومات NVIDIA. تتضمن هذه العملية تحويل نماذج NeMo إلى صيغة متوافقة مع TensorRT-LLM باستخدام وحدة nemo.export.
- انتهت فترة نشر برنامج الماجستير في القانونview
- نشر نماذج اللغة الكبيرة NeMo باستخدام NIM
- نشر نماذج اللغة الكبيرة NeMo باستخدام TensorRT-LLM
- نشر نماذج اللغة الكبيرة NeMo باستخدام vLLM
النماذج المدعومة
نماذج لغوية كبيرة
| نماذج لغوية كبيرة | التدريب المسبق وSFT | بي اي تي | تنسيق | تقارب تدريب FP8 | TRT/TRTLLM | تحويل من وإلى وجه العناق | تقييم |
|---|---|---|---|---|---|---|---|
| لاما3 8B/70B، لاما3.1 405B | نعم | نعم | x | نعم (تم التحقق جزئيًا) | نعم | كلاهما | نعم |
| ميكسترال 8x7B/8x22B | نعم | نعم | x | نعم (غير مؤكد) | نعم | كلاهما | نعم |
| نيموترون 3 8 ب | نعم | x | x | نعم (غير مؤكد) | x | كلاهما | نعم |
| نيموترون 4 340 ب | نعم | x | x | نعم (غير مؤكد) | x | كلاهما | نعم |
| بايتشوان2 7ب | نعم | نعم | x | نعم (غير مؤكد) | x | كلاهما | نعم |
| ChatGLM3 6B | نعم | نعم | x | نعم (غير مؤكد) | x | كلاهما | نعم |
| جيما 2B/7B | نعم | نعم | x | نعم (غير مؤكد) | نعم | كلاهما | نعم |
| جيما 2 2B/9B/27B | نعم | نعم | x | نعم (غير مؤكد) | x | كلاهما | نعم |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | نعم | نعم | x | نعم (غير مؤكد) | x | x | نعم |
| Phi3 mini 4k | x | نعم | x | نعم (غير مؤكد) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | نعم | نعم | x | نعم (غير مؤكد) | نعم | كلاهما | نعم |
| ستاركودر 15ب | نعم | نعم | x | نعم (غير مؤكد) | نعم | كلاهما | نعم |
| ستاركودر 2 3B/7B/15B | نعم | نعم | x | نعم (غير مؤكد) | نعم | كلاهما | نعم |
| بيرت 110م/340م | نعم | نعم | x | نعم (غير مؤكد) | x | كلاهما | x |
| T5 220M/3B/11B | نعم | نعم | x | x | x | x | x |
نماذج لغة الرؤية
| نماذج لغة الرؤية | التدريب المسبق وSFT | بي اي تي | تنسيق | تقارب تدريب FP8 | TRT/TRTLLM | تحويل من وإلى وجه العناق | تقييم |
|---|---|---|---|---|---|---|---|
| نيفا (LLaVA 1.5) | نعم | نعم | x | نعم (غير مؤكد) | x | من | x |
| لاما 3.2 رؤية 11B/90B | نعم | نعم | x | نعم (غير مؤكد) | x | من | x |
| LLaVA Next (LLaVA 1.6) | نعم | نعم | x | نعم (غير مؤكد) | x | من | x |
نماذج التضمين
| تضمين نماذج اللغة | التدريب المسبق وSFT | بي اي تي | تنسيق | تقارب تدريب FP8 | TRT/TRTLLM | تحويل من وإلى وجه العناق | تقييم |
|---|---|---|---|---|---|---|---|
| سبرت 340م | نعم | x | x | نعم (غير مؤكد) | x | كلاهما | x |
| لاما 3.2 تضمين 1ب | نعم | x | x | نعم (غير مؤكد) | x | كلاهما | x |
نماذج مؤسسة العالم
| نماذج مؤسسة العالم | ما بعد التدريب | الاستدلال المتسارع |
|---|---|---|
| الكون-1.0-انتشار-نص2عالم-7ب | نعم | نعم |
| الكون-1.0-انتشار-نص2عالم-14ب | نعم | نعم |
| كوزموس-1.0-انتشار-فيديو2عالم-7ب | قريباً | قريباً |
| كوزموس-1.0-انتشار-فيديو2عالم-14ب | قريباً | قريباً |
| كوزموس-1.0-الانحدار الذاتي-4ب | نعم | نعم |
| كوزموس-1.0-الانحدار الذاتي-فيديو2العالم-5ب | قريباً | قريباً |
| كوزموس-1.0-الانحدار الذاتي-12ب | نعم | نعم |
| كوزموس-1.0-الانحدار الذاتي-فيديو2العالم-13ب | قريباً | قريباً |
ملحوظة
يدعم NeMo أيضًا التدريب المسبق لكل من الهندسة المعمارية الانتشارية والانحدارية التلقائية text2world نماذج الأساس.
الذكاء الاصطناعي للكلام
يُعد تطوير نماذج الذكاء الاصطناعي التحادثي عمليةً معقدةً تتضمن تحديد النماذج وإنشائها وتدريبها ضمن مجالاتٍ محددة. تتطلب هذه العملية عادةً عدة تكرارات للوصول إلى مستوى عالٍ من الدقة. وغالبًا ما تتضمن تكراراتٍ متعددةً لتحقيق دقةٍ عالية، وضبطًا دقيقًا للمهام المختلفة والبيانات الخاصة بالمجال، وضمان أداء التدريب، وإعداد النماذج لنشر الاستدلال.
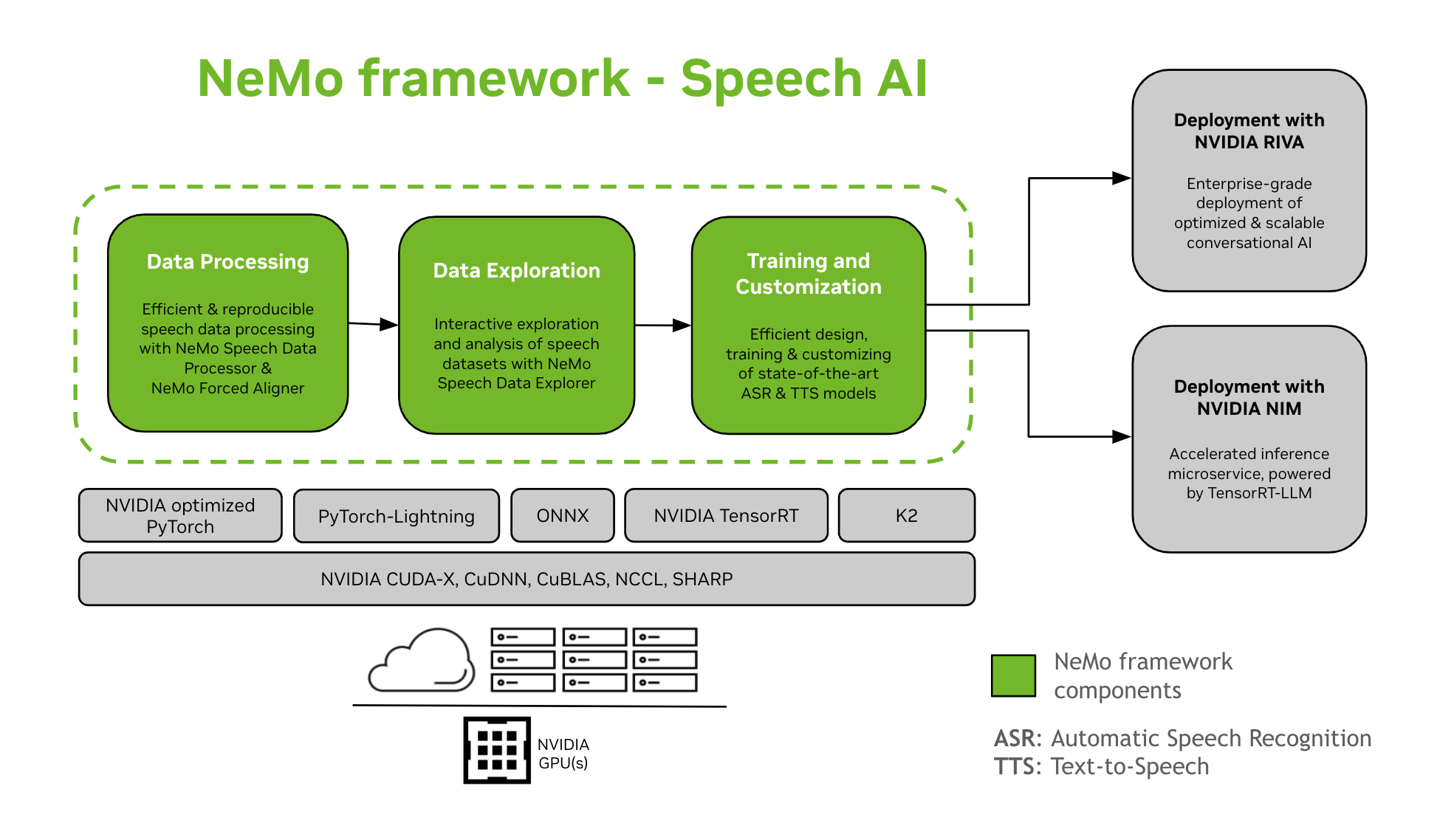
يوفر إطار عمل NeMo الدعم لتدريب نماذج الذكاء الاصطناعي للكلام وتخصيصها. ويشمل ذلك مهامًا مثل التعرف التلقائي على الكلام (ASR) وتوليف النص إلى كلام (TTS). كما يوفر انتقالًا سلسًا إلى النشر الإنتاجي على مستوى المؤسسات باستخدام NVIDIA Riva. ولمساعدة المطورين والباحثين، يتضمن إطار عمل NeMo نقاط تفتيش مُدربة مسبقًا على أحدث طراز، وأدوات لمعالجة بيانات الكلام القابلة للتكرار، وميزات للاستكشاف والتحليل التفاعلي لمجموعات بيانات الكلام. مكونات إطار عمل NeMo للذكاء الاصطناعي للكلام هي كما يلي:
التدريب والتخصيص
يحتوي إطار عمل NeMo على كل ما هو مطلوب لتدريب نماذج الكلام وتخصيصها (التعرف التلقائي على الكلام, تصنيف الكلام, التعرف على المتحدث, تدوين المتحدث، و تحويل النص إلى كلام) بطريقة قابلة للتكرار.
نماذج SOTA المدربة مسبقًا
- يوفر إطار عمل NeMo وصفات متطورة ونقاط تفتيش مدربة مسبقًا للعديد من التعرف التلقائي على الكلام و تحويل النص إلى كلام النماذج، بالإضافة إلى التعليمات حول كيفية تحميلها.
- أدوات الكلام
- يوفر إطار عمل NeMo مجموعة من الأدوات المفيدة لتطوير نماذج ASR وTTS، بما في ذلك:
- محاذاة نيمو القسرية (NFA) لتوليد وقت على مستوى الرمز والكلمة والقطعةampتحويل الكلام إلى صوت باستخدام نماذج التعرف التلقائي على الكلام المستندة إلى CTC من NeMo.
- معالج بيانات الكلام (SDP)مجموعة أدوات لتبسيط معالجة بيانات الكلام. تتيح لك تمثيل عمليات معالجة البيانات في ملف تكوين. file، تقليل الكود النمطي والسماح بإمكانية إعادة الإنتاج والمشاركة.
- مستكشف بيانات الكلام (SDE)، المستندة إلى Dash web تطبيق للاستكشاف والتحليل التفاعلي لمجموعات بيانات الكلام.
- أداة إنشاء مجموعة البيانات الذي يوفر وظيفة لمحاذاة الصوت الطويل fileقم بدمج النصوص مع النصوص المقابلة وتقسيمها إلى أجزاء أقصر مناسبة لتدريب نموذج التعرف التلقائي على الكلام (ASR).
- أداة المقارنة لنماذج التعرف على الكلام (ASR) لمقارنة تنبؤات نماذج التعرف على الكلام المختلفة على مستوى دقة الكلمة والنطق.
- مُقيِّم ASR لتقييم أداء نماذج التعرف التلقائي على الكلام والميزات الأخرى مثل اكتشاف نشاط الصوت.
- أداة تطبيع النص لتحويل النص من الشكل المكتوب إلى الشكل المنطوق والعكس (على سبيل المثال "31" مقابل "الحادي والثلاثون").
- المسار إلى النشر
- يمكن تحسين نماذج NeMo المُدرَّبة أو المُخصَّصة باستخدام إطار عمل NeMo ونشرها باستخدام NVIDIA Riva. تُوفِّر Riva حاويات ومخططات Helm مُصمَّمة خصيصًا لأتمتة خطوات النشر بضغطة زر.
مصادر أخرى
- نيمو:المستودع الرئيسي لإطار عمل NeMo
- نيمو-يجري:أداة لتكوين وإطلاق وإدارة تجارب التعلم الآلي الخاصة بك.
- محاذاة نيمو: مجموعة أدوات قابلة للتطوير لمواءمة النموذج بكفاءة
- نيمو-المشرف: مجموعة أدوات معالجة البيانات المسبقة وتنظيمها القابلة للتطوير لحاملي شهادة الماجستير في القانون
تواصل مع مجتمع NeMo، واطرح الأسئلة، واحصل على الدعم، أو أبلغ عن الأخطاء.
- مناقشات نيمو
- قضايا نيمو
لغات البرمجة وأطر العمل
- بايثون:الواجهة الرئيسية لاستخدام إطار عمل NeMo
- بايتورش:تم بناء إطار عمل NeMo على PyTorch
التراخيص
- مستودع NeMo على Github مرخص بموجب ترخيص Apache 2.0
- إطار عمل NeMo مرخص بموجب اتفاقية منتج NVIDIA AI. بسحب الحاوية واستخدامها، فإنك توافق على شروط وأحكام هذا الترخيص.
- تحتوي حاوية NeMo Framework على مواد Llama التي تحكمها اتفاقية ترخيص مجتمع Meta Llama3.
الحواشي
في الوقت الحالي، يعد دعم NeMo Curator وNeMo Aligner للنماذج متعددة الوسائط عملاً قيد التقدم وسوف يكون متاحًا قريبًا جدًا.
التعليمات
س: كيف يمكنني التحقق مما إذا كان نظامي متأثرًا بالثغرة الأمنية؟
ج: يمكنك التحقق من تأثر نظامك بالتحقق من إصدار إطار عمل NVIDIA NeMo المُثبّت. إذا كان الإصدار أقل من 24، فقد يكون نظامك مُعرّضًا للخطر.
س: من أبلغ عن مشكلة الأمان CVE-2025-23360؟
ج: تم الإبلاغ عن المشكلة الأمنية بواسطة Or Peles – JFrog Security. تُقدّر NVIDIA مساهمتهم.
س: كيف يمكنني تلقي إشعارات النشرة الأمنية المستقبلية؟
أ: قم بزيارة صفحة أمان منتج NVIDIA للاشتراك في إشعارات النشرة الأمنية والبقاء على اطلاع حول تحديثات أمان المنتج.
المستندات / الموارد
 | إطار عمل نيمو |
مراجع
- دليل المستخدمmanual.tools